Motivation
Current methods fail to sufficiently harness the feature sources from two information perspectives, which hinder further MRE development:
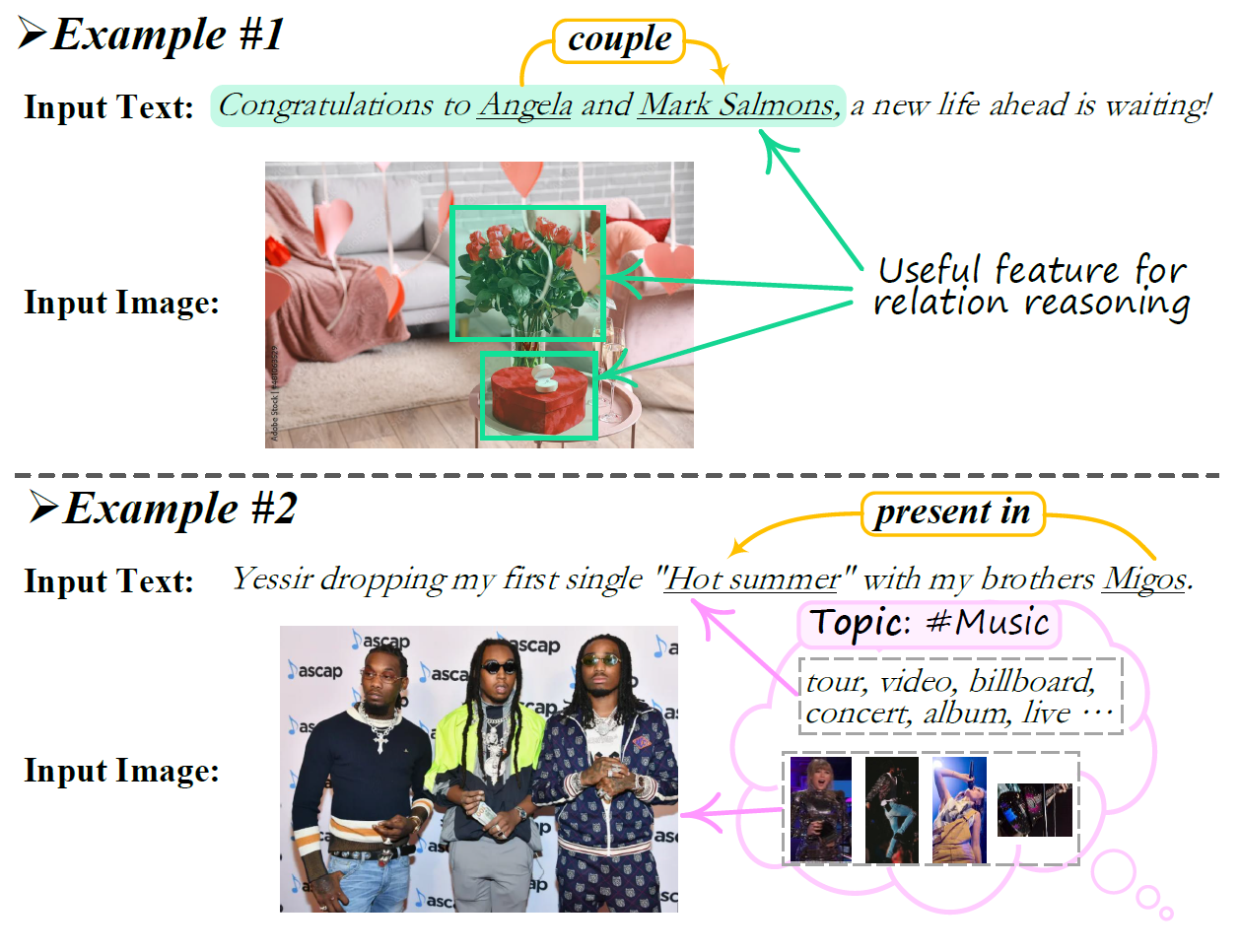
Existing research on multimodal relation extraction (MRE) faces two co-existing challenges, internal-information over-utilization and external-information under-exploitation. To combat that, we propose a novel framework that simultaneously implements the idea of internal-information screening and external-information exploiting. First, we represent the fine-grained semantic structures of the input image and text with the visual and textual scene graphs, which are further fused into a unified cross-modal graph (CMG). Based on CMG, we perform structure refinement with the guidance of the graph information bottleneck principle, actively denoising the less-informative features. Next, we perform topic modeling over the input image and text, incorporating latent multimodal topic features to enrich the contexts. On the benchmark MRE dataset, our system outperforms the current best model significantly. With further in-depth analyses, we reveal the great potential of our method for the MRE task.
Current methods fail to sufficiently harness the feature sources from two information perspectives, which hinder further MRE development:
We thus propose a novel framework for improving MRE, which consists of five parts:

Experimental results. Here are the main results, ablation study and some analyses:

Multimodal topic-keywords. Here are some textual and visual topic-keywords induced by the latent multimodal topic model (LAMO).

@inproceedings{WUAcl23MMRE,
author = {Shengqiong Wu, Hao Fei, Yixin Cao, Lidong Bing, Tat-Seng Chua},
title = {Information Screening whilst Exploiting! Multimodal Relation Extraction with Feature Denoising and Multimodal Topic Modeling},
journal = {Proceedings of the Annual Meeting of the Association for Computational Linguistics},
year = {2023},
}